Python 函数
为什么要使用函数
本节我们将介绍一个新的概念——函数。函数一词源自于英文单词"function",最初主要应用于数学领域,后来被引入到编程领域。在编程中,函数的含义比数学上更为广泛。
为什么我们需要使用函数呢?可以将创作一个项目比喻成盖一座大楼,如下图所示:

这个大楼由许多不同的部分组成,如房间、电梯、窗户等。这些部分相当于项目中的不同代码片段。例如,如果我们需要创建窗户的代码,可能会写出一段特定的代码来实现它。
在一座大楼中通常有许多窗户,它们的代码结构可能是相似的,因此我们会编写类似的代码来创建每个窗户。然而,当项目中存在大量重复的代码时,如何解决这个问题呢?有些人可能会尝试使用复制粘贴的方式,但这种做法并不适合。如果有很多类似的代码需要创建,使用复制粘贴会导致代码冗余且可读性差。因此,为了更好地管理和组织代码,我们需要引入函数的概念。函数可以帮助我们将重复使用的代码片段封装起来,以便在需要时调用。通过定义函数,我们可以在整个项目中多次调用相同的功能,而无需重复编写代码。这样不仅可以提高代码的可维护性和可读性,还能使项目结构更加清晰。因此,本章我们将深入介绍函数的相关内容。
函数的定义
函数通常被分为两类:内置函数和自定义函数。内置函数是Python自带的函数,包括一些常用功能如打印print函数、求长度len函数、求最大值max函数等,用户无需自行定义即可直接使用。而自定义函数则是根据个人需求定义的,用于实现特定功能。

需要注意的是,如果某些功能Python已经内置了相应函数,用户就不需要再自行定义,因为内置函数更为优雅高效。所以你需要尽量使用内置函数,当内置函数无法满足你的条件的时候,你再去自定义函数。
在Python中内置了许多函数,可以通过简单的操作来查看它们。在IDLE中,输入print(dir(__builtins__)),将会列出Python中的内置函数列表,如下图所示:
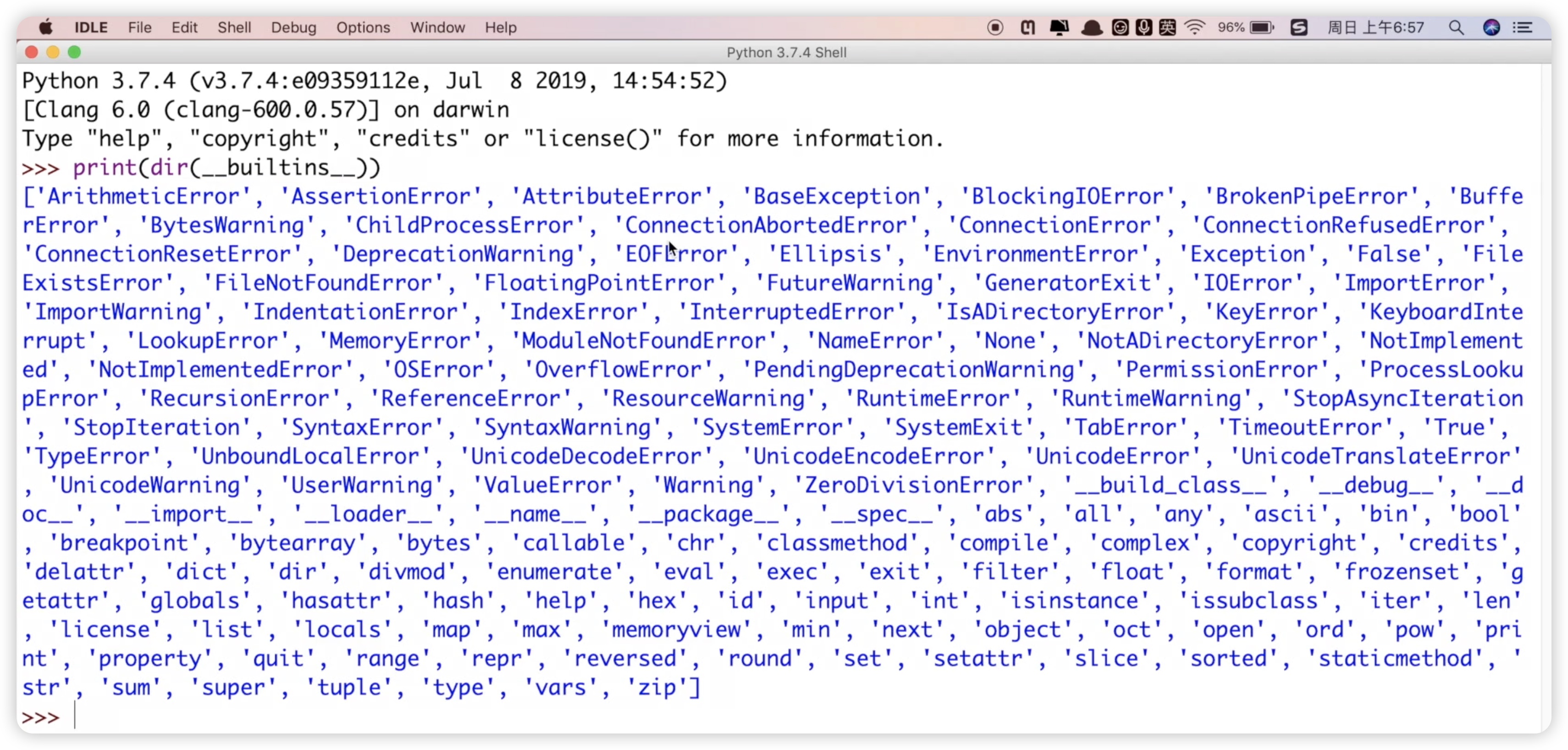
包括一系列常用函数如str字符串转换、tuple元组转换、type类型查看、set集合操作、字典操作、求最大值、list列表操作等。这些内置函数的使用能够大大简化编程过程,提高效率。
接下来我们来学习如何自定义函数,要自定义函数,需要遵循一定的格式。使用关键字def定义函数,后跟函数名称和小括号,然后是冒号。在冒号下方就是代码片段,比如说我们这里的代码片段是窗户的代码,这个函数就是用于实现创建一个窗户的具体功能。如下图所示:

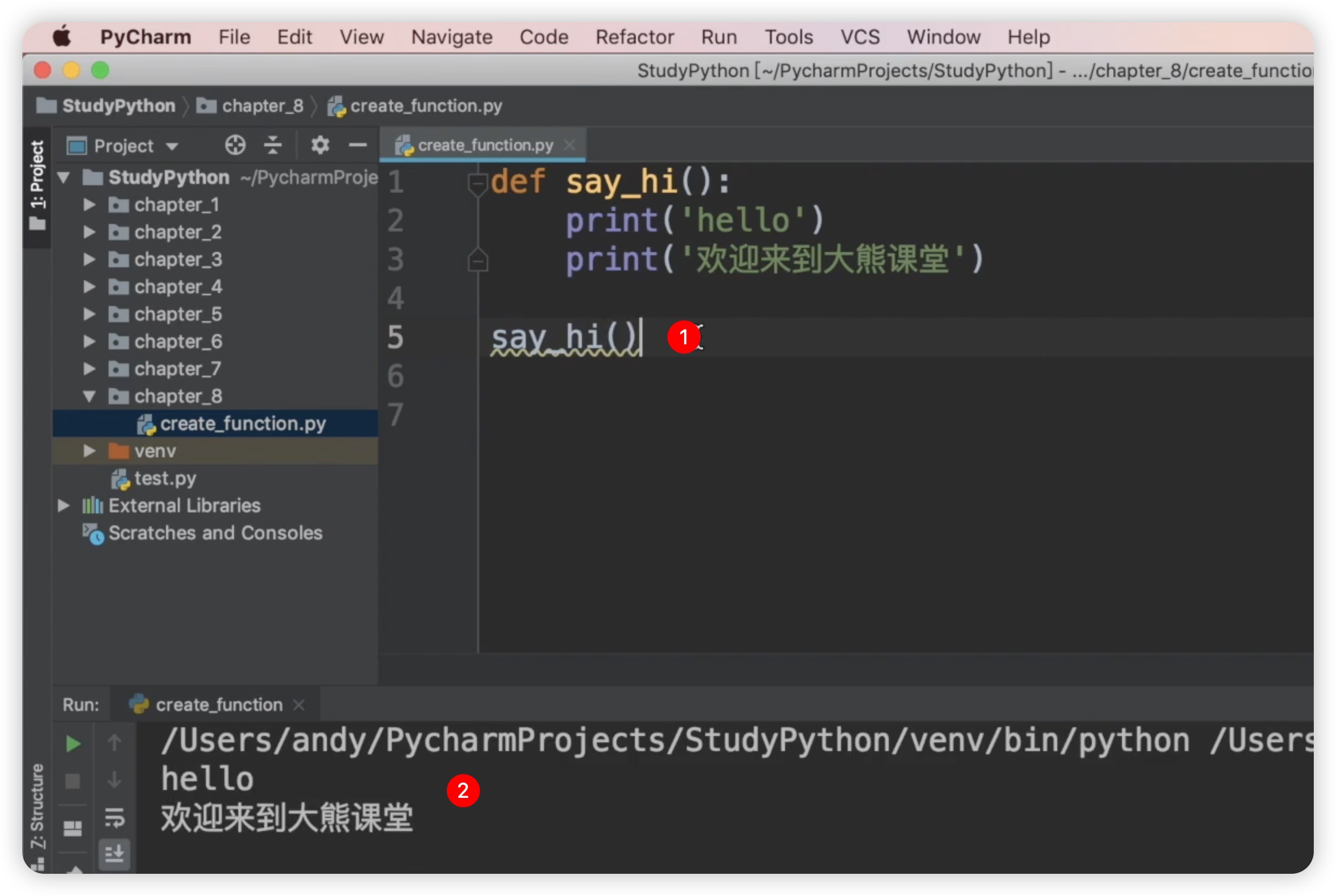
调用函数时,只需使用函数名即可。需要注意的是,函数必须先定义后调用,否则会出现NameError错误。
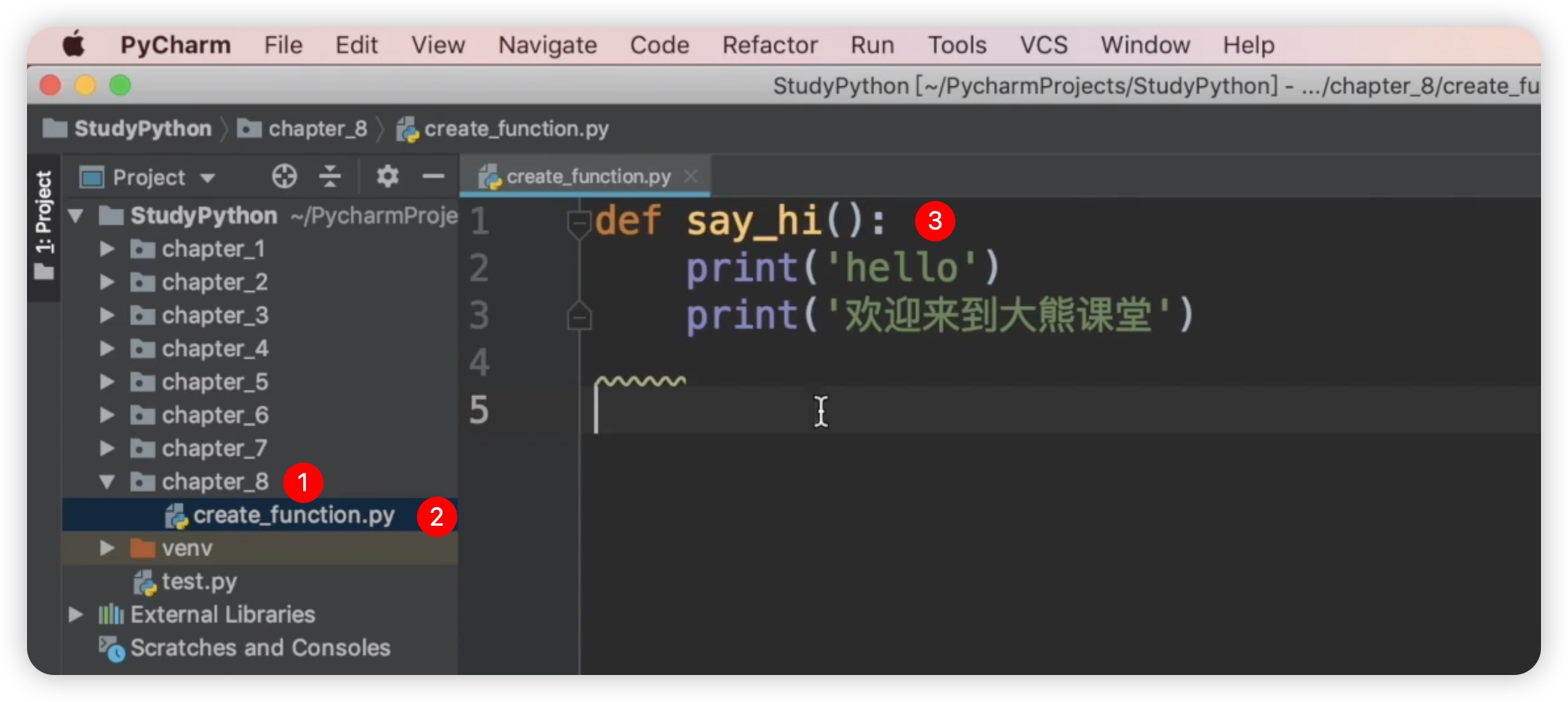
下面我们将在代码中定义一个函数。首先,我们需要创建一个新的目录,命名为"chapter"。在创建完成后,我们再创建一个Python文件,命名为"create_function"。我们首先创建一个比较简单的��函数。使用关键字def来定义函数,注意小伙伴们在创建函数名称的时候,我们通常使用小写字母加下划线的形式,比如说我要创建一个say_hi
两个单词之间用下划线来分割,在函数体内我们可以写很多代码,即函数要执行的代码。在这个例子中,我们简单地输出了两行内容:"hello" 和 "欢迎来到大熊课堂"。如下图所示:
但是,创建函数完成后,是否会自动输出下面的内容呢?不会。因为仅仅是创建了函数,但并没有调用它。只有在调用函数时,函数才会执行。接下来,我们调用这个函数。调用函数只需使用函数的名称,然后加上小括号。这样,函数就会被执行,并输出相应的内容。如下图所示:
下面我们将分析该函数的运行过程。为什么在函数定义完成后,内容不会自动输出?而在调用函数时,内容却会自动执行呢?为了更好地说明,我们仍然采用可视化的方式展示Python代码。首先,我们将代码粘贴到可视化工具中。在工具中,红色表示即将执行的代码。下一步将运行函数定义部分def say_hi。然后,我们点击“forward”按钮。如下图所示:

它指向一个内存地址,这个内存地址中存储的是一个函数,即say_hi函数。需要注意区分,这里的say_hi是一个变量名,而不是函数��名。此时,程序已经进入到函数体内部,然后继续执行。输出了第1个"hello world",再次点击“forward”按钮,又输出了第2个"欢迎来到大熊课堂"。如下图所示:
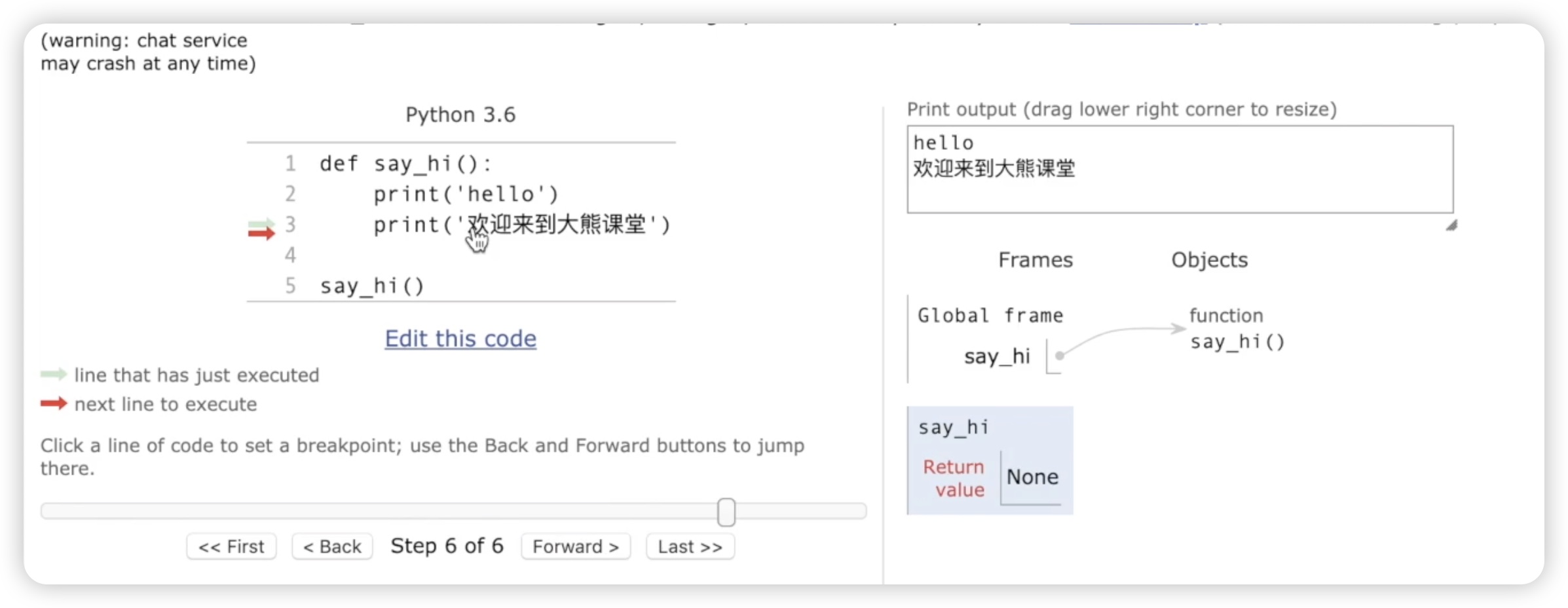
关于这个函数的返回值,是None。返回值的概念我们会在后面进行介绍。这里只需要知道返回值是None即可。通过这种方式,可以清楚地看到函数的执行流程。从函数的定义开始,程序会逐行执行,直到调用函数时才会执行函数体内的代码。
如果我们试图在定义函数之前就调用它,会发生什么呢?程序会报错:NameError: name 'say_hi' is not defined,因为在调用函数时,它还没有被定义。Python是按照从上到下的顺序执行代码的,因此必须先定义函数,再调用它。
在调用 say_hi 函数时,如果需要多次调用,可以使用 for 循环结构,例如连续调用十次。通过 for i in range 循环来多次调用 say_hi 函数,从而可以简化代码并实现重复执行的功能。代码如下:
def say_hi():
print('hello')
print('欢迎来到大熊课堂')
for i in range(10):
say_hi()
输出结果:
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
此外,函数的另一个作用是分解代码。举例来说,假设需要创建一座高楼,其中包含多个部分,如房间、电梯等。通过定义函数 create,可以分别创建不同的组件,并在需要时进行调用。例如,首先创建房间,输出相应的信息,然后再创建电梯,同样输出相应的信息。代码如下:
#创建高楼
def create butlding()
#创建房间
print('开始创建房间')
print('正在创建房间')
print('创建房间完成')
#创建曳梯
print('开始创建电梯')
print('正在创建电梯')
print('创建电梯完成')
输出结果:
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
hello
欢迎来到大熊课堂
通过调用函数,可以将原本冗长的代码分解为多个函数,每个函数实现一个特定功能,提高了代码的可读性和维护性。
在实际应用中,代码往往会变得复杂,包含大量业务逻辑。此时,将一个大的函数拆分为多个小的函数能够带来诸多好处。首先,每个函数实现一部分功能,实现了代码的复用性。例如,创建房间的功能可能在多个场景中都会用到,通过将其拆分为独立的函数,可以在需要时直接调用。其次,每个函数都实现单一职责,这样当出现问题时能够快速定位到具体的错误。最后,函数的拆分提高了代码的可读性,使得代码结构清晰明了,易于理解和维护。代码如下
# 创建高楼
def create_building():
# 创建房间
create_room()
# 创建电梯
create_stair()
def create_room():
print('开始创建房间')
print('正在创建房间')
print('创建房间完成')
def create_stair():
print('开始创建电梯')
print('正在创建电梯')
print('创建电梯完成')
create_building()
综上所述,函数的作用主要体现在两个方面。首先,最大化代码的重用性,最小化代码的冗余,实现了代码的高效复用。其次,通过函数的分解,将复杂的逻辑拆分为多个小的函数,使得代码结构清晰,易于理解和维护。这种分解能够提高代码的可读性和可维护性,是软件开发中常用的编程技巧之一。
通过改造窗户来认识函数的参数
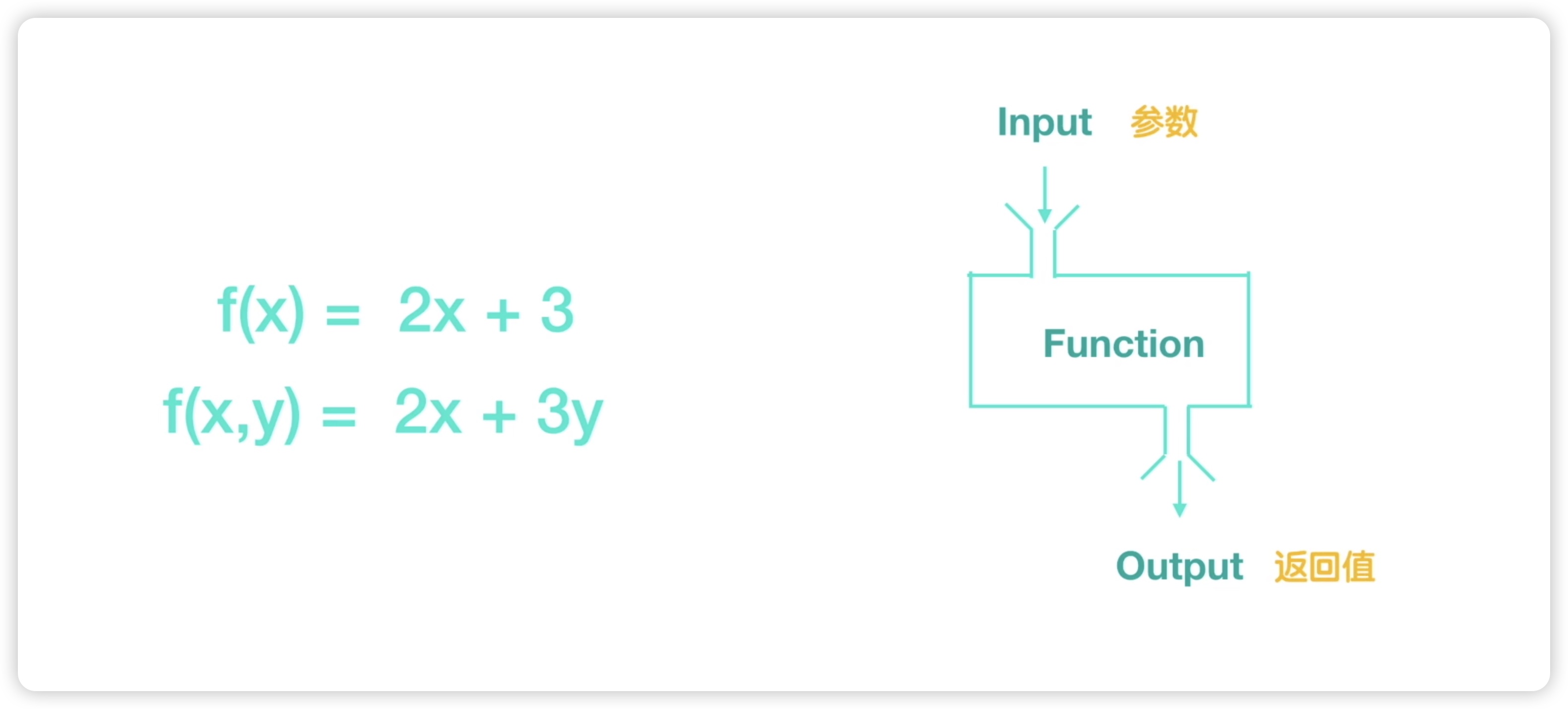
本节我们来介绍一下函数的参数,在介绍参数之前,我们来看一下数学上的意义,在数学上有个函数,f(x)=2x+3 这里左侧的f(x)它是随着x的变化而发生变化的,比如说当x等于1的时候,所以这里的f(x)它的值就是5,而x=2的时候,2×2+3=7,f(x)值就变成了7,这里的x在数学上就叫做自变量,而f(x)它就叫做因变量,它随着x变化而发生变化,接下来我们再来看一个f(x,y)=2x+3y,在这个函数中有两个自变量,一个是x,一个是y,而左侧的f(x,y),它是随着x和y,它们两个的变化而发生变化的。比如说当x=1 y=1的时候,结果就是5,当x=2,y=1的时候,结果就是7,这就是数学上的函数,对于数学上的函数,我们可以抽象为这样的意义,可以抽象为一个函数有一个入口和一个出口,我们给入口输入一些变量,经过函数的处理后,从出口输出结果。如下图所示:
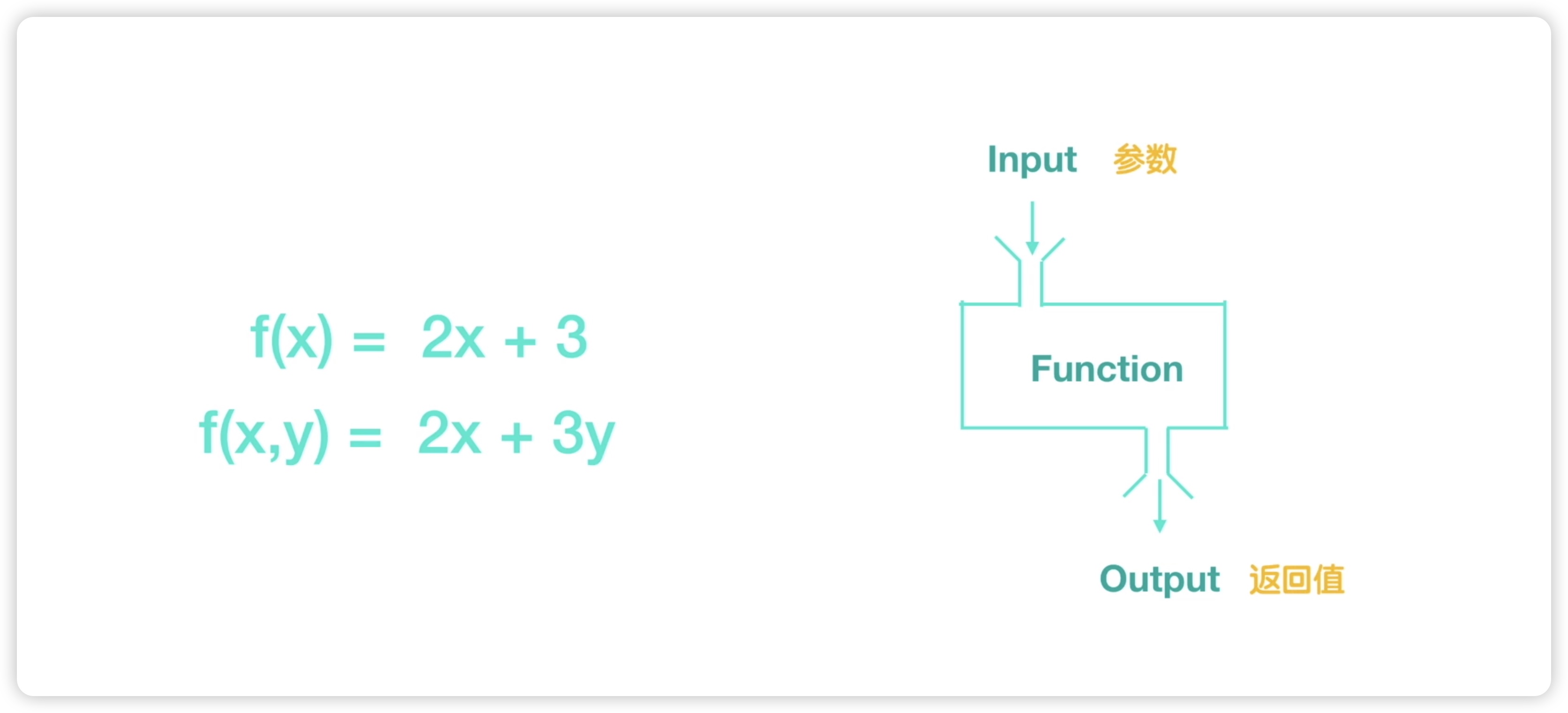
在编程领域,函数的概念比数学上更为广泛,它包含了数学上的函数。在数学上的输入,在编程领域中就是一个参数,而输出则相当于返回值。在本节中,我们先来介绍参数。我们以创建窗户的代码为例,假设在一个高楼中有许多窗户,如下图所示:

虽然它们都是窗户,但尺寸上有差异,比如左侧的窗户和右侧的窗户,左侧的尺寸较大,右侧的尺寸较小。难道我们要编写两个创建窗户的函数吗?显然这样的代码过于冗余。因此,针对这样的问题,我们可以使用函数的参数来解决。之前我们定义了一个名为 windows 的函数,其中包含窗户的代码,通过调用该函数可以创建一个窗户。如下图所示:
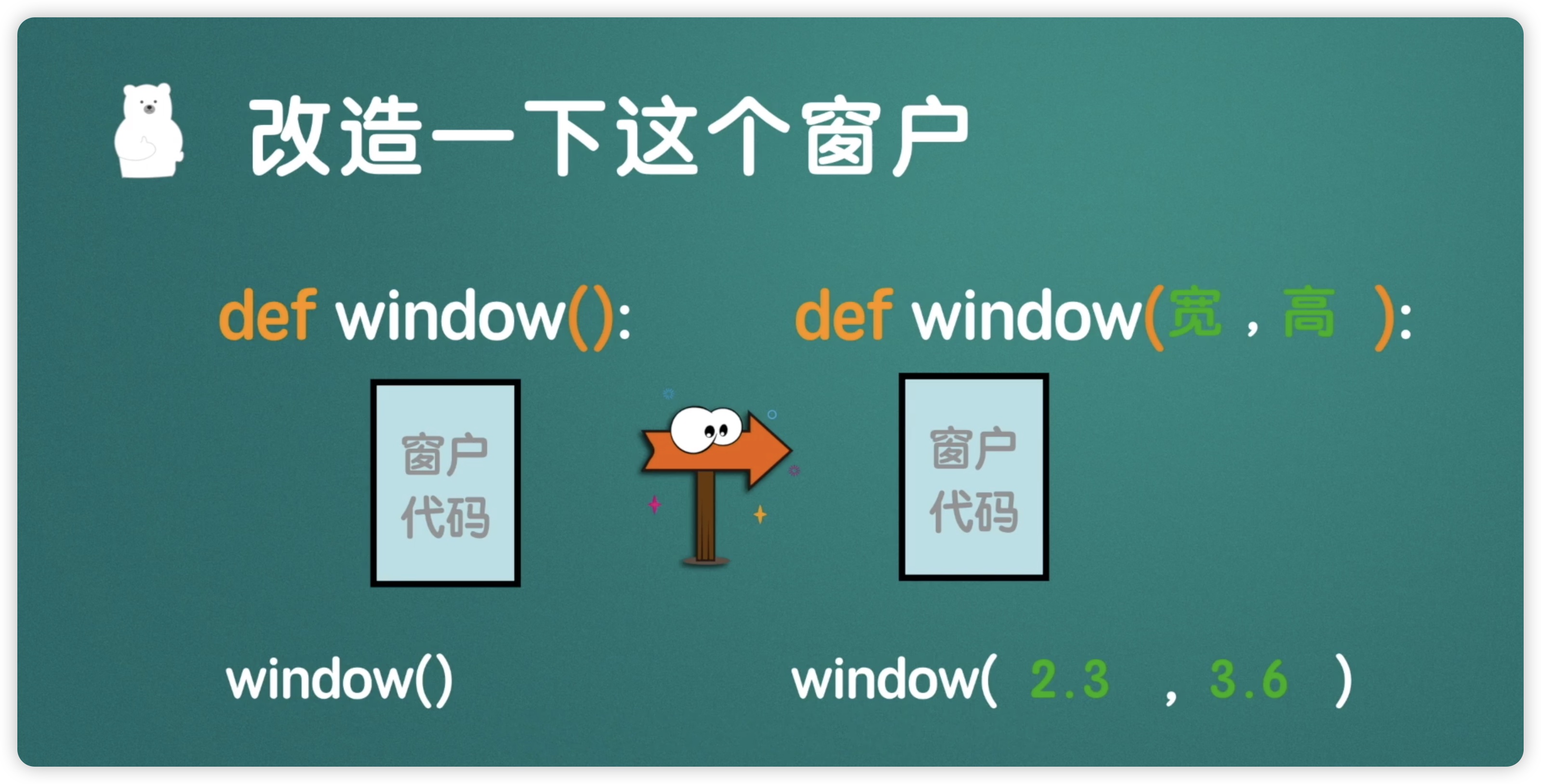
现在,我们对这个函数进行改造,在函数中添加了两个参数,一个是宽度,一个是高度。当调用这个窗户函数时,根据需要添加两个数值,这些数值与函数前面定义的宽度和高度相对应。例如,如果我们传入宽度为 2.3,高度为 3.6,那么创建的窗户就是宽 2.3、高 3.6 的窗户。通过这些参数,我们可以自主地改变窗户的尺寸,这就是参数的作用,它相当于函数的输入,经过函数的处理后,最终产生一个输出。
函数普通参数形式
下面我们将讨论Python中函数参数的不同形式。首先是普通参数。我们在代码中进行演示。首先,我们创建一个Python文件,命名为create_args,这里的"args"是参数的缩写。我们先来看第一种情况,即普通参数的情况。以前面的代码为例,我们有一个名为say_hi的函数。通过调用say_hi,我们会输出"hello 欢迎来到大熊课堂"。如果我们想要向某个人表示欢迎呢?比如,如果是Andy,我们就可以写成"hello, Andy 欢迎来到大熊课堂"。现在,让我调用这个函数say_hi。结果是"hello, Andy 欢迎来到大熊课堂"。代码如下:
# 普通参数
def say_hi():
print(f'hello,Andy')
print('欢迎来到大熊课堂')
say_hi()
如果我把"Andy"改成"Jack Ma"呢?代码如下:
# 普通参数
def say_hi():
print(f'hello,Jack Ma')
print('欢迎来到大熊课堂')
say_hi()
运行后,结果就变成了"hello, Jack Ma 欢迎来到大熊课堂"。在这些例子中,我们是写死的,那么如何才能实现动态的变化呢?这就是参数的用武之地。我们给这个函数设定一个参数叫做name,然后直接使用name,通过f-string的方式,变成name,然后输出"hello, name 欢迎来到大熊课堂"。在调用这个函数时,我们需要给name赋一个值。如果不赋值,会提示缺少参数的错误。因此,你需要给name赋一个值,比如"Andy"。再次运行,结果就是"hello, Andy 欢迎来到大熊课堂"。代码如下:
# 普通带一个参数
def say_hi(name):
print(f'hello,{name}')
print('欢迎来到大熊课堂')
say_hi('Andy')
如果把"Andy"改成"Jack Ma"呢?运行后,结果就是"hello, Jack Ma 欢迎来到大熊课堂"。也就是说,这里的值会赋给name,然后输出后面的语句。这就是函数参数传值的方式。
# 普通带一个参数
def say_hi(name):
print(f'hello,{name}')
print('欢迎来到大熊课堂')
say_hi('JackMa')
如果我们定义两个参数呢?我们以创建窗户的代码为例。定义一个函数create_window,窗户有一个宽度和一个高度。我们用width表示宽,height表示高,并输出"窗户的宽是 width 高是 height"。代码如下:
# 定义一个函数create_window,该函数接受两个参数:窗户的宽度和高度
def create_window(width, height):
# 打印窗户的宽度和高度,使用f-string格式化输出
print(f'窗口的宽是{width};高是{height}')
# 调用create_window函数,并传递参数值为2和1
create_window(1, 2)
输出结果:
窗口的宽是1;高是2
接下来我们调用这个函数create_window,给它传递一个值。运行结果是"窗户的宽是1 高是2"。如果我们修改值为2和1呢?运行后,结果就变成了"窗户的宽是2 高是1"。代码如下:
# 定义一个函数create_window,该函数接受两个参数:窗户的宽度和高度
def create_window(width, height):
# 打印窗户的宽度和高度,使用f-string格式化输出
print(f'窗口的宽是{width};高是{height}')
# 调用create_window函数,并传递参数值为2和1
create_window(2, 1)
输出结果:
窗口的宽是2;高是1
也就是说,在函数中,调用时传递的值的顺序非常重要。第一个值会匹配到函数定义的第一个参数,第二个值会匹配到函数定义中的第二个参数。多个参数的情况也是类似的,它们会一一匹配。
函数默认参数形式
本节我们将介绍函数的参数。接下来我们将讨论第二种参数类型,即默认参数。在前面定义参数时,我们注意到��必须为每个参数赋值,确保一一对应,否则会出现错误。然而,使用默认参数可以解决这个问题。比如说,我们来定义一个函数来计算一个小时工一天的工资,即一天的工资等于当天的工作时长乘以每小时的薪水。现在我们来定义一个名为total的函数。它有两个参数:hour表示时间,salary表示每小时的薪水。然后我们输出"今天的薪水是",使用hour乘以salary得出工作的时长乘以每小时工资,即他今天的总薪水。接下来我们定义total,假设工作8小时,那每小时的薪水是?代码如下:
# 默认参数
def total(hour,salary):
print(f'今天的薪水是{hour*salary}元')
total(8,10)
输出结果:
今天的薪水是80元
运行后,结果显示今天的薪水为80元。现在我们要为这个函数添加默认参数。假设这个店是麦当劳,那么麦当劳临时工的薪水就是每小时8元,所以我们直接给参数salary赋值8元。这里的工作时长是不固定的,但薪水是固定的。在传递参数时,第二个值我们可以不赋值。调用函数total时,total只有一个参数。这个参数会匹配到第一个参数hour,即工作了8小时,而薪水是默认的8元。代码如下;
# 默认参数
def total(hour,salary):
print(f'今天的薪水是{hour*salary=8}元')
total(8)
输出结果:
今天的薪水是64元
运行后,结果显示今天的薪水是64元,因为每小时默认薪水是8元。但是,如果某天麦当劳需要更多的人手,而且现在招不到更多的人,那么薪水可能会调整为每小时10元,这时你就不能使用默认值了。你可以直接传递新的薪水值。
# 默认参数
def total(hour,salary=8):
print(f'今天的薪水是{hour*salary}元')
total(8,10)
输出结果:
今天的薪水是80元
从这个例子中,我们可以看出默认参数的作用。在传递参数时,如果不填写值,它将使用定义中的默认值。如果填写了值,它将替换掉默认值。这就是函数的默认参数。
函数关键字参数形式
本节我们将介绍函数的参数。接下来我们来看第三种形式,即关键字参数。关键字参数用于解决函数参数顺序的问题。在前面,我们为参数赋值时,参数都是一一对应的,顺序非常重要。有时,我们需要根据实际情况调整参数的顺序,这时就需要使用关键字参数了。
举个例子,我们要输出一个学生的名和姓。我们定义一个函数student,该函数有两个参数,一个是first_name,另一个是last_name。我们使用f-string来输出"first name is xxx, last name is xxx"。接下来我们调用这个函数。在调用函数时,普通的方式是按照参数顺序来赋值,比如"first name"是"Andy","last name"是"feng"。代码如下:
# 关键字参数
def student(firstname,lastname):
print(f'firstanme is {firstname};lastname is {lastname}')
student('andy','Feng')
输出结果:
firstanme is andy; lastname is Feng
运行后,输出结果是"first name is Andy, last name is feng",这是普通的形式。现在,如果我想自主定义参数的顺序,可以这样做:在参数前面直接给它赋值,例如first_name = "Andy",last_name = "feng",然后再调用函数。代码如下:
# 关键字参数
def student(firstname,lastname):
print(f'firstanme is {firstname};lastname is {lastname}')
student(lastname='Feng',firstname='andy')
输出结果:
firstanme is andy; lastname is Feng
运行后,结果是一样的。通过这种方式,参数的顺序就不再重要了,我们可以随意调整它们的位置。使用关键字参数与前面定义的函数有很大不同。前面定义的函数是一一匹配的,而现在,由于我们使用了关键字参数,可以直接为每个参数赋值,让它们与函数定义中的参数一一对应。使用关键字参数有许多优点。首先,顺序可以不固定,这在参数较多时非常方便。其次,它提高了代码的可读性。使用关键字参数,参数的意义变得非常明显,提高了代码的可读性。其他人在阅读你的代码时,可以很清楚地知道每个参数的含义,而不用去猜测。
函数不定长参数形式
接下来我们将介绍本节的一个难点,即不定长参数。不定长参数指的是参数的长度不固定,我们无法确定有多少参数。因为函数的参数可以是各种不同类型的数据。在前面,我们使用的都是字符串类型的参数。但如果你使用了一个字典类型呢?
举个例子,现在我们来定义一个函数my_function。这里的参数是不固定的,我们使用一个*号来表示,后面跟一个参数名称,通常叫做args。因为args是参数 arguments 这个单词的缩写。默认情况下我们都使用这个args。接下来我们来遍历这个args,代码如下:
# 不定长参数
def my_function(*args):
for arg in args:
print(arg)
my_function('hello','welcome','to','daxiong')
输出结果:
hello
welcome
to
daxiong
现在我们来运行一下,输出的结果就是 "hello welcome to daxiong",也就是说这里的args,它就相当于一个容器,在这个容器中包含了你传递的任何参数。如果我再加一个"thank you",再来运行,结果就变成了 "hello welcome to daxiong thank you",这个长度是可以任意变化的。
这里的args就相当于一个容器,长度是不固定的。下面我们就使用了一个for循环,将容器中的内容依次输出了。为了更清楚地了解,我们来打印一下这个容器args,看它是个什么类型的数据。代码如下:
# 不定长参数
def my_function(*args):
print(args)
for arg in args:
print(arg)
my_function('hello','welcome','to','daxiong')
输出结果:
('hello', 'welcome', 'to', 'daxiong')
hello
welcome
to
daxiong
运行后,结果你会发现这是一个元组,循环遍历的是这个元组。这是不定长参数的第一种情况,只用一个*,加一个参数名,根据惯例它是args,然后就会将这里的参数全部变成一个元组。这是第一种情况。
接下来我们再来看第二种情况,使用两个*号的情况。使用两个*号,它表示传递的参数也是一个不定长参数,但是这个参数的格式呢,它是一个字典,所以我们使用**kwargs来表示。kwargs中的w表示keywords。接下来,我们再遍历一下这个kwargs。那么kwargs它是一个什么类型的数据呢?我们来打印一下kwargs。代码如下:
# 不定长参数
def my_function(*args,**kwargs):
print(args)
print(kwargs)
for arg in args:
print(arg)
my_function('hello','welcome','to','daxiong',lastname='Feng',firstname='andy')
输出结果:
('hello', 'welcome', 'to', 'daxiong')
{'lastname': 'Feng', 'firstname': 'andy'}
hello
welcome
to
daxiong
接下来我们看一下,kwargs如何给它赋值。在赋值的时候我们使用键值对的方式,比如说,我们就赋值这里的last_name和first_name。现在我们来运�行一下,结果就说出了第一个args它是一个元组,元组里的值就是我们这里默认传递的"hello welcome to 大熊 thank you",而接下来的kwargs它是什么呢?它是一个字典。字典中的键名是 key word,对应的键值是 feng 和 Andy,也就是我们这里定义的last_name是feng,first_name是Andy,它把这里的前面的值转化为键名,后面的值转换为键值。
那么我们要获取这里的键名和键值呢,应该怎么做?依然使用for循环遍历字典,这里遍历的时候就使用key和value了,分别获取键名和键值 in kwargs 这是一个字典,此时我要使用字典的一个item方法,它能够获取键名和键值,然后我输出一下 print 使用 f-string,指向 value。代码如下;
# 不定长参数
def my_function(*args,**kwargs):
print(args)
print(kwargs)
for arg in args:
print(arg)
for key, value in kwargs.items():
print(f'{key}->{value}')
my_function('hello','welcome','to','daxiong',lastname='Feng',firstname='andy')
输出结果:
('hello', 'welcome', 'to', 'daxiong')
{'lastname': 'Feng', 'firstname': 'andy'}
hello
welcome
to
daxiong
lastname->Feng
firstname->andy
首先输出一个元组,再来输出一个字典。接下来遍历这个元组,遍历完成以后,再下面就是遍历字典了。遍历字典的时候我们有key有value,key value 这样你就获取到字典中的每一个值了。这里需要小伙伴们注意的是,在获取字典的键名和键值的时候,我们需要使用item方法,然后遍历它,才能够依次获取 key 和 value。
如果我这个函数中除了不定长的内容,还有一些定长的参数呢?比如说前面我们还有一个宽度 width,还有一个高度 height,那这两个值应该如何传入呢?对于这种原始的情况,还是按我们原始的方式,函数会依次匹配到前面的第一个和第二个值作为width和height。比如说我们第一�个width赋值为 2.3,第二个赋值为 4.5。代码如下:
# 不定长参数
def my_function(width,height,*args,**kwargs):
print(width)
print(height)
print(args)
print(kwargs)
my_function(2.3,4.5,'hello','welcome','to','daxiong','thankyou',lastname='Feng',firstname='andy')
输出结果:
2.3
4.5
('hello', 'welcome', 'to', 'daxiong', 'thankyou')
{'lastname': 'Feng', 'firstname': 'andy'}
再来运行,然后再输出一下这里的width和height。也就是说它是按顺序依次匹配的,先匹配到两个width和height,后面的这些值全部赋值给元组,在后面的这里使用关键字参数的全部赋值给字典。这就是不定参数函数定义的方式。如果你还不是很理解,我们还可以通过可视化的方式来进一步加深理解。如下图所示:
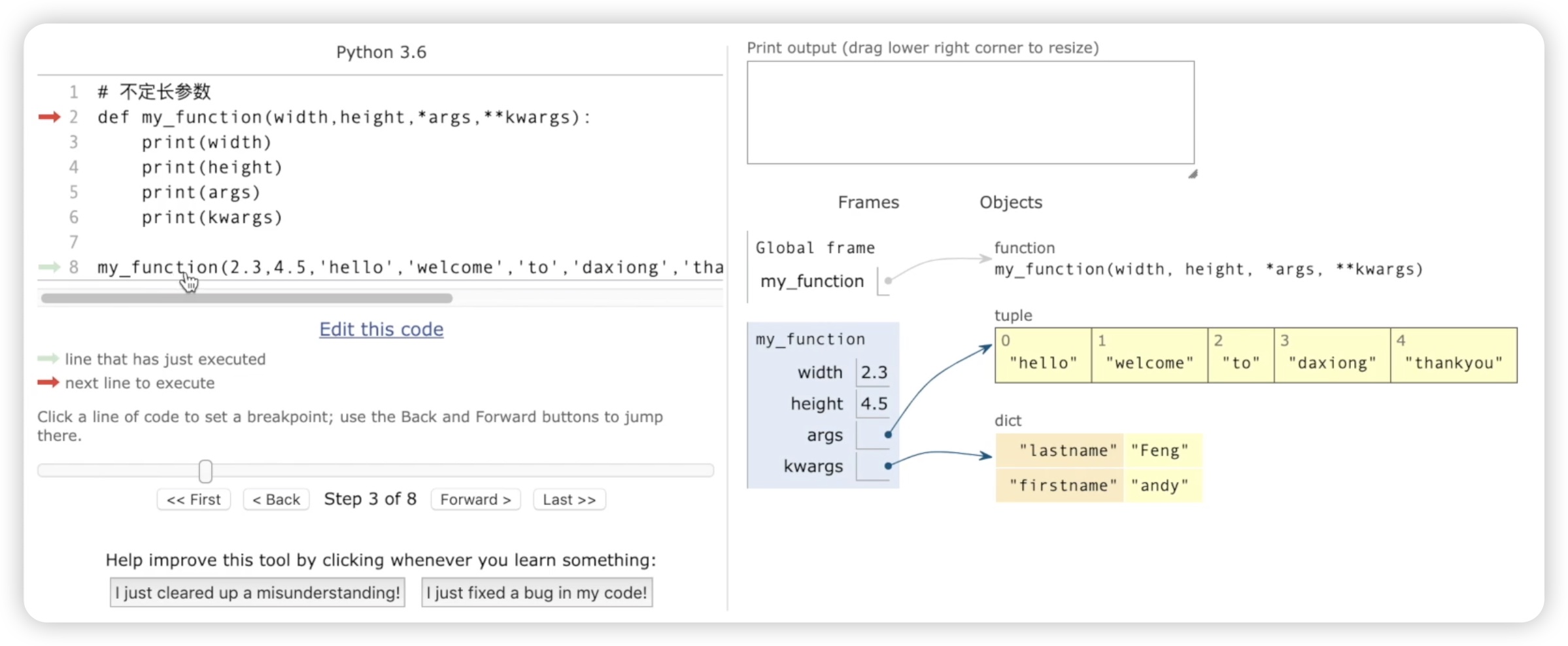
在右侧我们看到有一个 my_function 它的变量,这个变量指向一个函数叫做 my_function,函数中有很多参数。接下来呢,我们开始下一步调用这个函数。调用函数的时候我们看到这是 my_function 是函数,有这么多参数。第一个参数 width 它自动赋值为 2.3,第二个参数 height 如何自动赋值为 4.5。这里的 args 它会指向一个元组,看到这里有个 tuple。然后它的值分别是 "hello welcome to 大熊 thank you"。然后 kwargs 呢?它指向的是一个字典,在字典中有键名 last_name,键值是 feng,还有��个键名 first_name,键值是 Andy。通过这种可视化的方式,我们就可以非常清晰地理解函数不定长参数,它是如何运行的。
四种参数形式总结
函数参数主要有四种方式。首先是普通参数,它们按照顺序逐个赋值。其次是默认参数,即给参数设置默认值,在参数未被指定时,将直接采用默认值。第三种方式是使用关键字参数,这样函数的参数顺序可以改变,并且提高了代码的可读性。最后是不定长参数,分为两种情况。一种是使用单个星号(*)加一个变量名(通常约定为args),表示参数将被收集到一个元组中。另一种是使用两个星号(**)加一个变量名(通常默认为kwargs),表示参数将被收集到一个字典中。
函数的返回值
本节我们学习了函数的返回值。函数通过处理输入产生输出,输入是函数的参数,而输出则是函数的返回值。返回值是指函数完成任务后得出的结果。如下图所示:
函数的返回值语法结构如下:首先定义一个函数,然后编写程序代码,在最后使用return语句返回结果。返回的地方是函数的调用者处,即函数运行完成后将结果返回给调用者。这是函数返回值的基本原理。如下图所示:

下面我们将在代码中查看函数的返回值。我们要创建一个名为return_val.py文件,其中包含一个函数,用于计算圆的面积。我们都知道圆的面积公式是πr²。首先,我们设定π的值为3.14,然后定义一个名为area的函数,用于计算圆的面积,其中r是半径参数,平方使用两个*号表示。接下来,我们使用return语句返回计算得到的面积值。代码如下:
# 求圆的面积
pi = 3.14
def area(r):
return pi * (r ** 2)
print(area(2))
输出结果:
12.56
然后我们可以调用这个函数,将半径r设置为2,我们将结果打印输出,得到的值是12.56。这个程序的运行过程如何呢?首先定义了一个变量π,然后定义了一个名为area的函数,这个函数用于计算圆的面积。在调用这个函数时,传入了参数2作为半径r的值,然后计算出结果,使用return语句将结果返回给调用者。调用者再将结果打印输出。
接下来,我们以可视化的方式再次审视这个函数的运行过程。我们点击可视化按钮后,开始执行代码。首先定义了π的值为3.14,然后定义了一个名为area的函数。执行area函数时,传入了参数2作为半径r的值,计算出了结果,如下图所示:
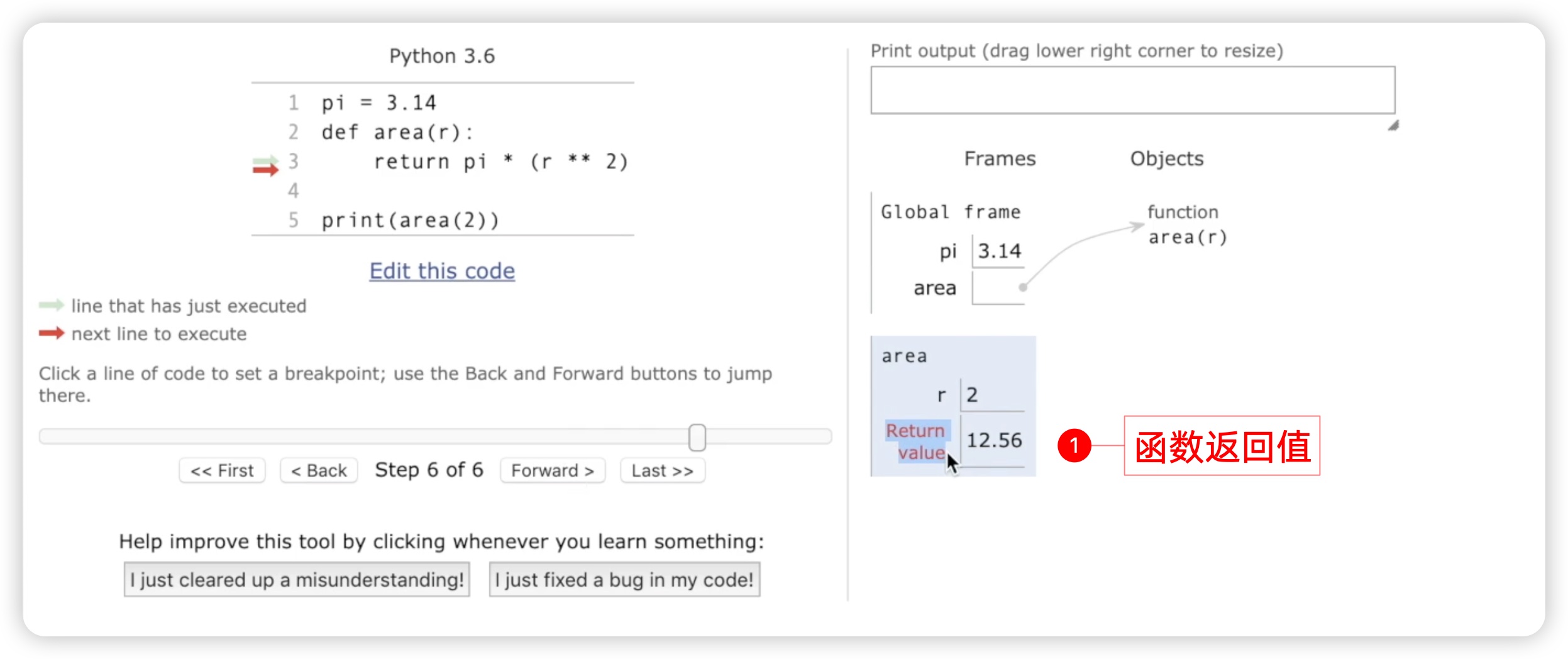
并返回给调用者。最后,我们看到输出的结果是一个返回值12.56。
下面我们来讨论输出多个返回值的情况。我们将编写一个函数,其功能是将分钟转换为时和分的形式。具体而言,对于给定的分钟数,我们要将其转换为小时和分钟的形式。我们定义了一个名为transform_minute的函数,它接收一个参数,即分钟数,我们将其命名为minute。接下来,我们开始进行转换。在此之前,需要了解一下小时和分钟之间的转换关系,即一小时等于60分钟。例如,对于100分钟,我们知道它等于1小时加上40分钟。同样地,对于200分钟,我们知道它等于3小时加上20分钟。通过这些例子,我们可以观察到,将分钟转换为小时时,需要取其整数部分,这时可以使用整除运算符,即双斜线 //,它表示向下取整。比如,对于200分钟,除以60后,得到3,即3小时,剩余的分钟数为20。接着,我们计算剩余的分钟数,这样我们就得到了小时和分钟的值。分钟的计算可以通过取余操作完成。例如,对于100分钟,对60取余后得到40,对于200分钟,对60取余后得到20。这是因为200分钟可以转换为3小时和20分钟。通过这种方式,我们可以快速地将分钟转换为小时和分钟。代码如下:
# 将分钟转化为时-分 100分钟=1小时40分 1小时=60分钟 100/60
def transform_minute(minute):
hours = minute // 60
minutes = minute % 60
print(f'{minute}分钟可以转化为{hours}小时{minutes}分钟')
transform_minute (200)|
输出结果:
200分钟可以转化为3小时20分钟
接下来,我们输出转换后的小时和分钟。我们调用这个函数,传递不同的分钟数进行测试。当输入为200分钟时,输出为3小时20分钟,符合预期。另外,当输入为50分钟时,输出为0小时50分钟,也符合预期。这个函数没有问题。
然而,通常情况下我们会给这个函数一个返回值,因为在后续可能会用到转换后的小时和分钟值。比如说,可能只需要小时值,不需要分钟值。因此,通常我们不会在函数内部直接输出内容,而是以返回值的形式将其返回。我们使用return语句来返回值,可以返回多个值,它们之间使用逗号进行分隔。返回值会返回到调用函数的位置。代码如下:
# 将分钟转化为时-分 100分钟=1小时40分 1小时=60分钟 100/60
def transform_minute(minute):
hours = minute // 60
minutes = minute % 60
return hours,minutes
print(transform_minute(50))
输出结果:
(0, 50)
我们对得出的结果对返回的元组进行拆包,获取小时和分钟的值,然后可以对它们进行单独的输出。代码如下:
# 将分钟转化为时-分 100分钟=1小时40分 1小时=60分钟 100/60
def transform_minute(minute):
hours = minute // 60
minutes = minute % 60
return hours,minutes
hours,minutes = transform_minute(200)
print(f"hours is {hours}")
输出结果:
hours is 3
这样做的好处在于,提高了函数的灵活性,使得调用者可以根据需要对返回值进行进一步的操作。如果函数没有return返回值,默认返回的是None。代码如下:
# 将分钟转化为时-分 100分钟=1小时40分 1小时=60分钟 100/60
def transform_minute(minute):
hours = minute // 60
minutes = minute % 60
print(transform_minute(200))
输出结果:
None
因此,在一般情况下,函数会包含return语句用于返回结果。
函数的作用域
本节我们将探讨函数的作用域。作用域这一概念涉及到变量的范围,在某一范围内变量发挥作用。我们将重点介绍两个方面:局部变量和全局变量。
首先,我们来看局部变量。在一段示例代码中,我们定义了两个函数test1和test2。在test1函数中有一个变量a,赋值为300,在test2函数中有两个变量,a赋值为100,b赋值为300。这些变量都是局部变量,即它们仅在各自函数的内部有效。举个类比,可以将这种关系比作是《宰相刘罗锅》中的刘墉和和珅,两者官职都是正一品,彼此独立,各自有管辖范围。因此,在不同函数内部定义的同名变量相互独立,互不影响。如下图所示:

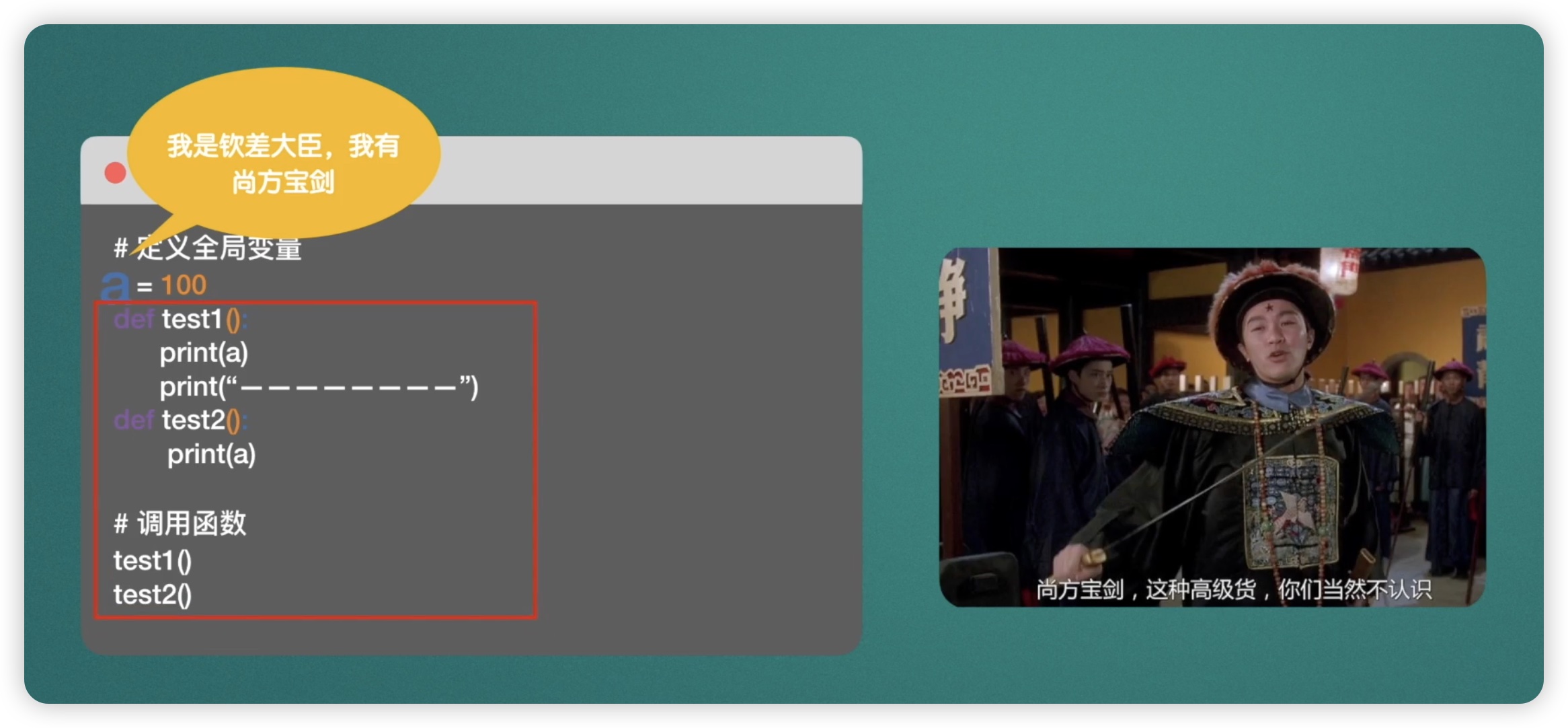
接下来我们将探究另一个函数��中的全局变量。在代码中我们可以看到,有两个函数外部定义了一个变量a,其值为100。然而,在test1和test2函数内部并没有定义变量a,但我们仍然可以输出变量a的值。这表明函数外部的a是一个全局变量,可以在任何函数内部使用。从概念上来说,这里的a就好比是一位钦差大臣,手持尚方宝剑,可以在任何地方发挥作用。因此,全局变量的作用在于它们可以跨越函数的边界,对整个代码文件起作用。如下图所示:
我们接着在代码中演示了如何使用局部变量和全局变量。首先,我们创建了一个Python文件,命名为local VS global。然后我们定义了两个函数,test1和test2,代码如下:
def test1():
a = 100 # 局部变量
def test2():
a = 300 # 局部变量
test1()
test2()
输出结果:
100
300
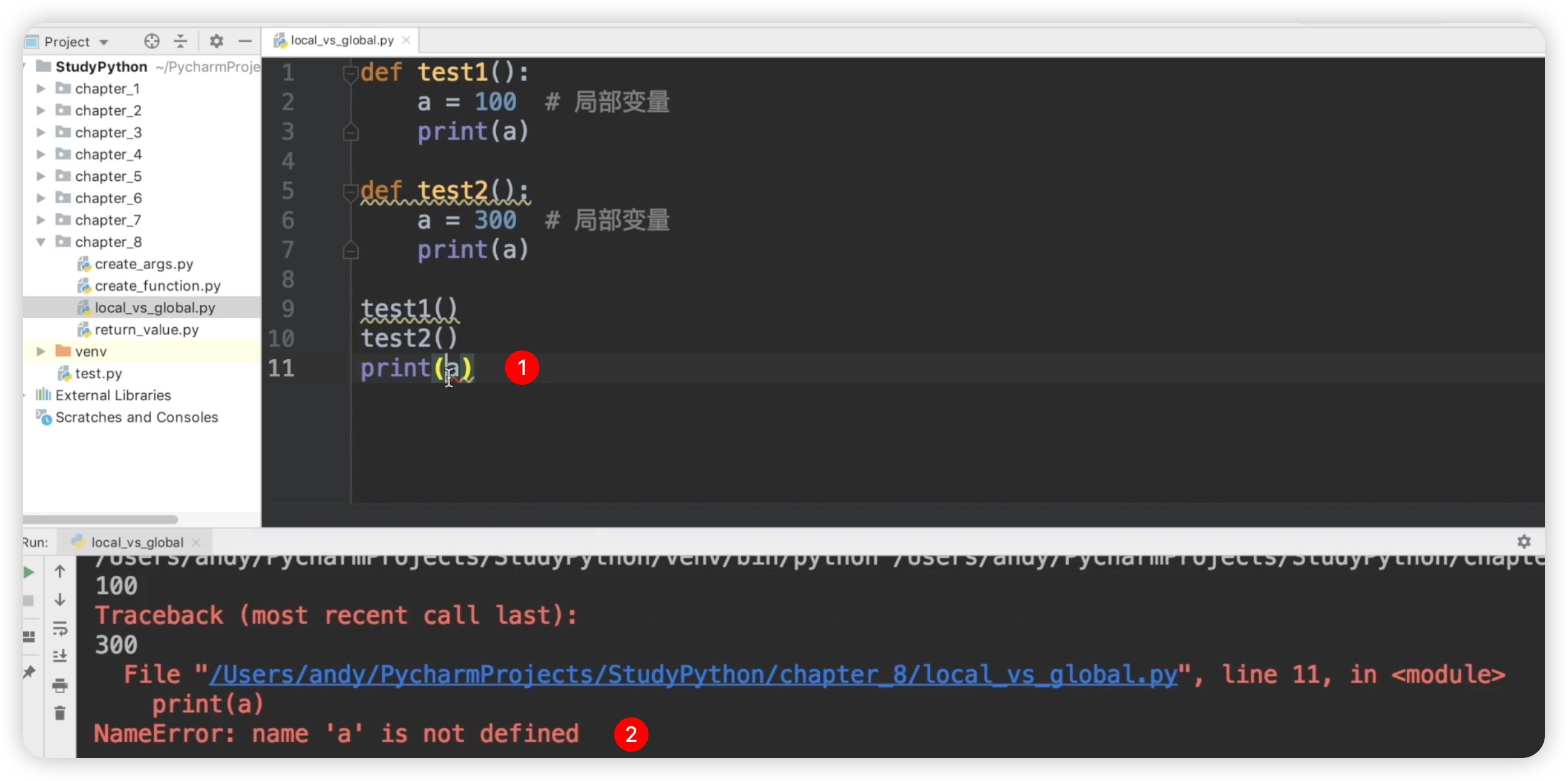
在这些函数内部分别创建了局部变量a并赋值。接着我们调用了test1和test2函数,并观察到输出结果分别为100和300,这证实了它们是局部变量。值得注意的是,局部变量的作用范围仅限于函数内部,这是很容易理解的。我们尝试在函数外部输出变量a,结果报错了。错误信息显示为NameError: name 'a' is not defined,这是因为在函数外部无法访问函数内部定义的局部变量。因此,这里的a是未定义的,导致了报错。这进一步印证了局部变量只在函数内部有效的特点。如下图所示:
接下来我们来学习全局变量,全局变量是在函数外部定义的变量,在整个代码文件中都可以访问。我们在代码中创建了一个全局变量a,并输出了它的值。代码如下:
a = 1 # 全局变量
def test1():
a = 100 # 局部变量
def test2():
a = 300 # 局部变量
test1()
test2()
print(a)
输出结果:
100
300
1
其中第一个100是test1函数中的a值,而最后一个1则是全局变��量a的值。这突显了局部变量和全局变量之间的优先级问题:在函数内部,尽管存在全局变量,但如果函数内部定义了同名局部变量,则最终输出结果将优先考虑局部变量的值。如果函数内部没有定义该变量,则会查找全局变量,若无则会报错。
接下来我们来学习如何在函数内部修改全局变量。使用关键字global声明全局变量后,即可在函数内部对其进行修改。我们通过代码示例演示了这一操作,代码如下:
a = 1 # 全局变量
def test1():
global a
a = 100
print(a)
def test2():
a = 300 # 局部变量
print(a)
test1()
test2()
print(a)
输出结果:
100
300
100
运行结果表明修改已成功。在成功修改后,当我将test2函数中的a注释掉并运行时,输出的值也变成了100。现在让我们来分析程序的执行过程。首先,程序按顺序从上往下执行。从第一行开始,将a赋值为1,它是一个全局变量。然后继续向下执行,遇到def关键字时,会创建两个函数对象,分别命名为test1和test2。但是此时并不会执行函数体内的内容,只是创建了函数对象。程序执行到这里就完成了,接着继续执行,再次遇到def时会创建test2函数对象,同样函数体内的内容不会执行。只有在调用函数时,函数体内的内容才会执行。接下来程序继续执行,当遇到test1()时,表示调用函数test1,然后执行test1函数体内的内容。首先会遇到global a声明,表示在函数内部使用的a是全局变量。对全局变量a进行操作,将其赋值为100,将全局变量a的值由1变为100。然后继续输出a,结果为100,对应着输出的第一个100。函数执行完毕后,控制权返回给调用者,即程序的下一行,再次调用test2函数,输出结果为第二个100,因为test2函数中的a是全局变��量,此时值为100。函数执行完毕后,返回给调用者,程序继续执行下一行,输出a,最终输出第三个100。这就是函数的执行过程。通过这个例子,我们知道要修改全局变量,需要使用global关键字声明,并对其进行修改。
如果不使用global关键字会发生什么变化呢?现在我们来测试一下。代码如下:
a = 1 # 全局变量
def test1():
a += 1
print(a)
def test2():
a = 300 # 局部变量
print(a)
test1()
test2()
print(a)
结果会出现localError,因为local variable a是局部变量,在赋值之前未进行定义,无法对其进行操作。接着我们添加global关键字并再次运行,此时a全变成了2,因为在这里对a进行了加1操作。
接下来我们再考虑一种特殊情况,如果全局变量的值是可变类型会发生什么变化呢?让我们来试一下,重新定义一个变量l,赋值为一个列表[1, 2, 3],然后对其进行操作,添加一个值并输出,代码如下:
a = 1 # 全局变量
#可变类型列表
l = [1,2,3]
def test1():
l.append(4)
print(l)
def test2():
a = 300 # 局部变量
print(a)
test1()
test2()
print(a)
输出结果:
[1, 2, 3, 4]
300
1
你会发现输出的结果不会报错,因为l是一个可变类型,即使没有使用global关键字,也可以在函数内部对其进行修改。这是因为对于可变类型,即使修改了其值,变量的指向并没有发生改变。因此,对于可变类型的全局变量,即使不使用global关键字,也可以在函数内部对其进行修改。
综上所述,局部变量是在函数内部定义的临时变量,不同函数间可以有相同名称的局部变量而互不影响。全局变量是在函数外部定义的变量,对于不可变类型的全局变量,在修改时需要使用global关键字,而对于可变类型的全��局变量,即使不使用global关键字也可以在函数内部进行修改。
函数的嵌套
本节我们将介绍函数的嵌套。在之前我们学习了if语句、while语句和for循环的嵌套,类似地,函数的嵌套指的是函数内部包含其他函数。本节我们主要讨论两个方面的内容:第一个是函数内部调用其他函数,第二个是在函数内部定义函数。
首先,让我们在代码中直接演示。在之前的函数创建例子中,我们已经讲解过一个创建高楼的例子。在这个例子中,我们定义了一个名为create_building的函数,在其内部调用了两个其他函数:create_room用于创建房间,create_stair用于创建楼梯。最后,我们调用了create_building函数。代码如下:
# 创建高楼
def create_building():
# 创建房间
create_room()
# 创建电梯
create_stair()
def create_room():
print('开始创建房间')
print('正在创建房间')
print('创建房间完成')
def create_stair():
print('开始创建电梯')
print('正在创建电梯')
print('创建电梯完成')
create_building()
程序执行顺序是从上往下的。首先从第一行开始执行,遇到def关键字时,会创建对应的函数对象,并将其指向一个变量,但是函数体内的代码不会执行。依次执行下去,直到调用create_building函数时,程序会跳转到该函数体内开始执行。在函数内部调用其他函数时,控制权会传递给被调用函数,执行完后再返回给调用者。这个过程会一直持续,直到所有函数执行完毕,最终输出结果。这种在函数内部调用其他函数的过程通常称为函数的��嵌套调用。这个流程相对简单,只要按照顺序执行,就能够理解其内容。
接下来我们看第二个方面:在函数内部定义函数。我们创建一个新文件,命名为nested_function。首先定义一个函数test1,输出一行内容表示开始执行。然后在其内部再定义一个函数test2,同样输出一行内容表示开始执行,test2在test1函数内部是一个新的函数。由于在函数内部定义的函数只能在该函数内部调用,因此在test1函数内调用test2函数。然后我们调用test1函数,代码如下:
def test1():
print("test1开始执行")
def test2():
print("test2开始执行")
test2()
test1()
输出结果:
test1开始执行
test2开始执行
当运行程序时,首先会输出test1开始执行,接着test2开始执行,最后输出test1。如果直接调用test2函数会报错,因为test2函数只在test1函数内部可见,无法在外部直接调用。
现在让我们进一步思考一下。假设在test2函数内部有一个变量a,并将其赋值为100,然后输出它的值。代码如下:
def test1():
print("test1开始执行")
def test2():
a=100
print("test2开始执行")
print(f'test2内部变量a的值是{a}')
test2()
test1()
输出结果:
test1开始执行
test2开始执行
test2内部变量a的值是100
接下来,如果在test2函数外部还有一个变量a,并将其赋值为10,代码如下:
def test1():
a=10
print("test1开始执�行")
print(f'test1内部变量a的值是{a}')
def test2():
a=100
print("test2开始执行")
print(f'test2内部变量a的值是{a}')
test2()
test1()
输出结果:
test1开始执行
test1内部变量a的值是10
test2开始执行
test2内部变量a的值是100
结果显示在test1中,a的值是10,在test2中,a的值是100。这和之前介绍的全局变量和局部变量的概念基本相同。如果我将test2函数注释掉a=100,使其内部没有变量a,然后运行,看一下它是否会调用函数外部的a。结果输出都是10,那就说明在函数内部如果没有a,它会去函数外部查找。
接下来我们思考一下,如果在test2内部修改外部的a,应该怎么办呢?尝试使用之前介绍的global关键字会起作用吗?让我们试一下。我们在test2内部加上global a,然后进行修改。代码如下:
def test1():
a=10
print("test1开始执行")
print(f'test1内部变量a的值是{a}')
def test2():
global a
a=100
print("test2开始执行")
print(f'test2内部变量a的值是{a}')
test2()
print(f'test1内部变量a的值是{a}')
test1()
输出结果:
test1开始执行
test1内部变量a的值是10
test2开始执行
test2内部变量a的值是100
test1内部变量a的值是10
结果发现原来的a是10,在使用global后,并没有起作用,这与之前介绍的作用域的内容不同。这里不能使用关键字global,而需要使用另一个关键字,叫做nonlocal。修改代码如下:
def test1():
a = 10
print('test1开始执行')
print(f'test1内部变量a的值是{a}')
def test2():
nonlocal a
a = 100
print('test2开始执行')
print(f'test2内部变量a的值是{a}')
test2()
print(f'test1内部变量a的值是{a}')
test1()
输出结果:
test1开始执行
test1内部变量a的值是10
test2开始执行
test2内部变量a的值是100
test1内部变量a的值是100
结果显示,第一次运行时a是10,刚运行完test2后,外部的a的值也变成了100,这说明我们修改成功了。以上就是函数嵌套的两个方面内容。
函数的递归
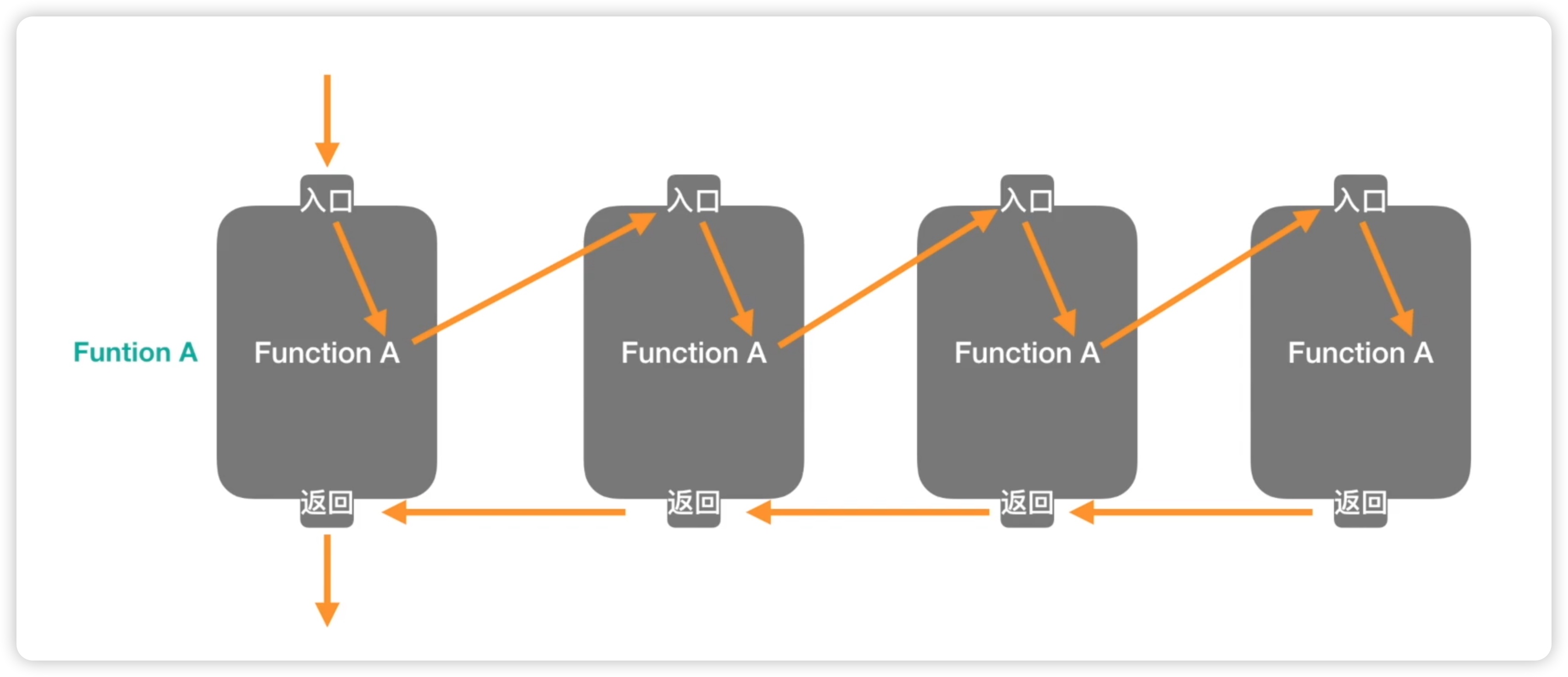
在上一节课程中,我们介绍了函数的嵌套调用,即在一个函数内部调用其他函数。现在我们要讨论的是在一个函数内部调用函数本身,这就是递归函数。接下来,我们通过一个动画来展示递归函数的工作原理。在动画中,我们有一个名为a的函数,它具有特殊的性质,在函数内部再次调用了函数a。程序执行的过程如下:首先从入口处进入函数,然后执行函数体,其中调用了函数a,即调用函数本身。为了更清晰地演示,我们在其他位置再次调用了function a。在函数a内部,又调用了函数a,因此又创建了一个function a。当执行完最后一次调用后,函数需要返回给其调用者,然后逐级返回,直到最初的调用者。这就是递归函数的工作原理。如下图所示:
接下来我们来看一下递归函数的应用,递归函数的经典应用之一是求阶乘。阶乘在初中阶段已经学过,即n的阶乘由1一直乘到n。如下图所示:
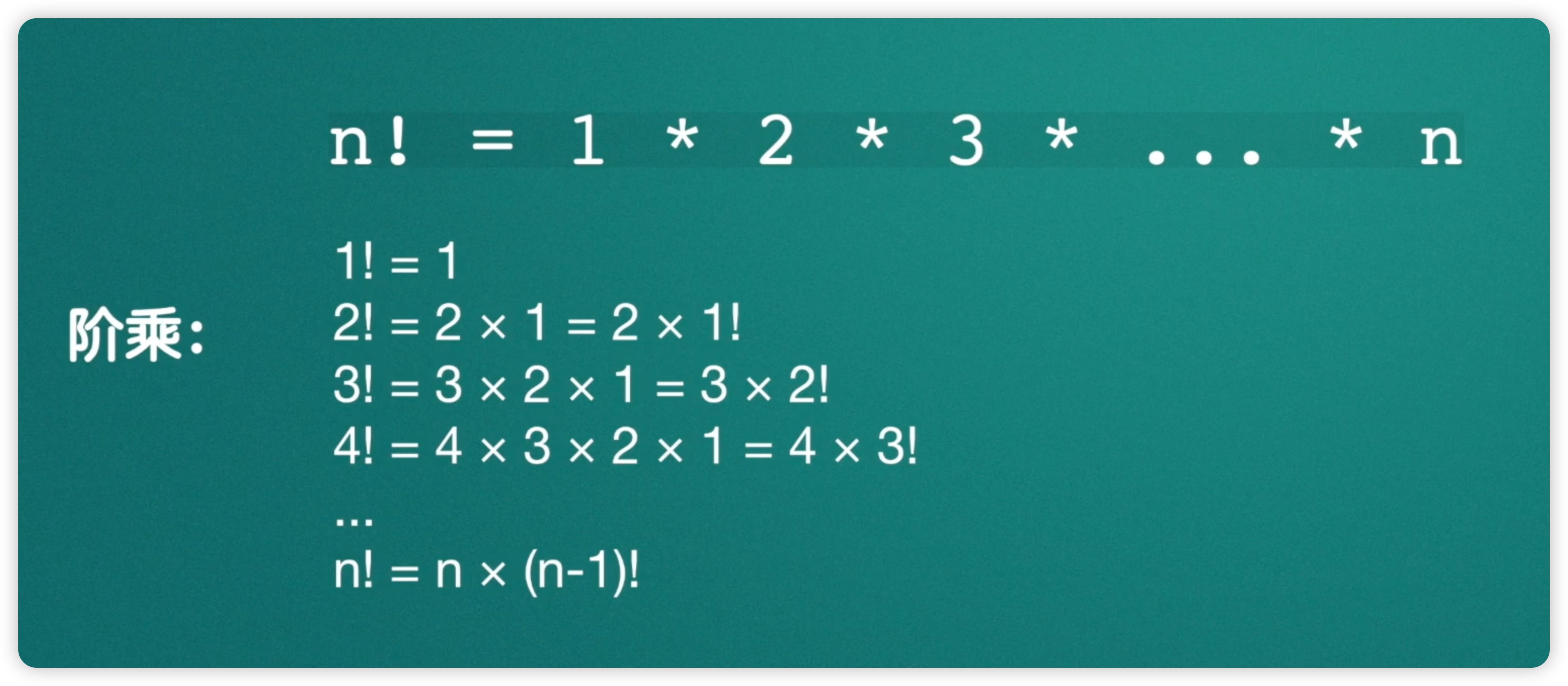
在代码中,我们定义了一个名为recursion的Python文件,其中实现了阶乘的函数。下面我们来定义一个函数fact,它的参数n表示我们要求阶乘的数值,因此n是一个可变的数值。我们首先要处理一个特殊情况,即当n等于1时,它的阶乘就是1。因此,我们使用if语句来判断n是否等于1,如果是的话,直接返回1。否则,我们设定一个变量result,它的值就是n乘以n-1的阶乘,同样使用fact(n-1)来表示。最后,我们返回这个result。代码如下:
# 定义一个阶乘函数 fact,参数为 n
def fact(n):
# 判断是否达到递归出口,即 n 是否为 1
if n == 1:
return 1 # 若 n 为 1,则返回 1
# 若 n 不为 1,则计算 n * fact(n-1),即递归调用 fact 函数
result = n * fact(n-1)
return result # 返回计算结果
# 调用 fact 函数,并将结果赋值给变量 result
result = fact(3)
# 输出结果
print(result)
现在我们来看一下这个函数。函数名字叫做fact,在函数体内,我们又调用了fact函数,唯一不同的是它们的参数发生了变化。fact(n)表示求n的阶乘,即n的阶乘等于n乘以n-1的阶乘。因此,在函数内调用了这个函数自身,这就是一个递归函数。接下来我们来运行一下。我们调用fact函数,假设n=2,然后将它传递给变量result。现在我们来输出一下这个result。运行结果显示2的阶乘就是2,如果是3的阶乘,结果是6。
这就是函数递归调用的流程。递归函数的优点是定义简单,逻辑清晰。在理论上所有的递归函数都可以写成循环的方式,但是在使用递归函数的时候,小伙伴们需要注意防止栈溢出。比如我们求的是三的阶乘,那如果我们求10000的阶乘呢?我们运行一下,直接为我们报错:RecursionError: maximum recursion depth exceeded in comparison,这里的意思就是超出了最大的递归深度,导致栈溢出。所以在使用递归函数的时候,要注意不要使用太多的递归次数。